
Claude Skills Deep Dive: Progressive Loading and the MCP Alternative

TL;DR
Claude Skills use a 3-tier progressive loading architecture: 100 tokens of metadata loaded at startup, full instructions (<5k tokens) loaded on-demand when triggered, and linked reference files loaded only when needed. This beats MCP's 10K+ token upfront cost for document generation workflows, while MCP wins for external services and real-time data.
Skills use 100 tokens of metadata. Then load instructions only when triggered.
That’s a 99% reduction in upfront context cost compared to MCP servers. If you’ve been burning 10K-15K tokens on tool loading before your first message even lands, this is the architectural fix you didn’t know existed.
100 tokens vs 15,000 tokens. Skills load 150x less upfront. That’s not an optimization—it’s a different architecture.
Here’s why it matters and when Skills should replace your MCP servers.
The Token Economics Problem
I spent six months building MCP servers for everything. Context engineering, filesystem operations, web scraping. Every MCP server adds 10K-15K tokens to your context window upfront. Before Claude reads a single message.
Four MCP servers? That’s 40,000-60,000 tokens consumed before you type “hello.” On a 200K context window, you’ve burned 20-30% of your budget on overhead.
Then I discovered Skills. Same progressive disclosure pattern I use in my context engineering work, but built into Claude’s architecture. The difference is dramatic.
Here’s the data:
MCP Token Cost (Upfront)
- Server registration: ~2K tokens
- Tool schemas: ~8K-13K tokens per server
- Total before first message: 10K-15K tokens
Skills Token Cost (Progressive)
- Metadata at startup: ~100 tokens (64 char name + 1024 char description)
- Full instructions when triggered: less than 5K tokens
- Reference files: 0 tokens until read
The difference? Skills load on-demand. MCP loads everything upfront.
How Skills Architecture Works
Skills use a 3-tier progressive loading system. Here’s the exact structure:
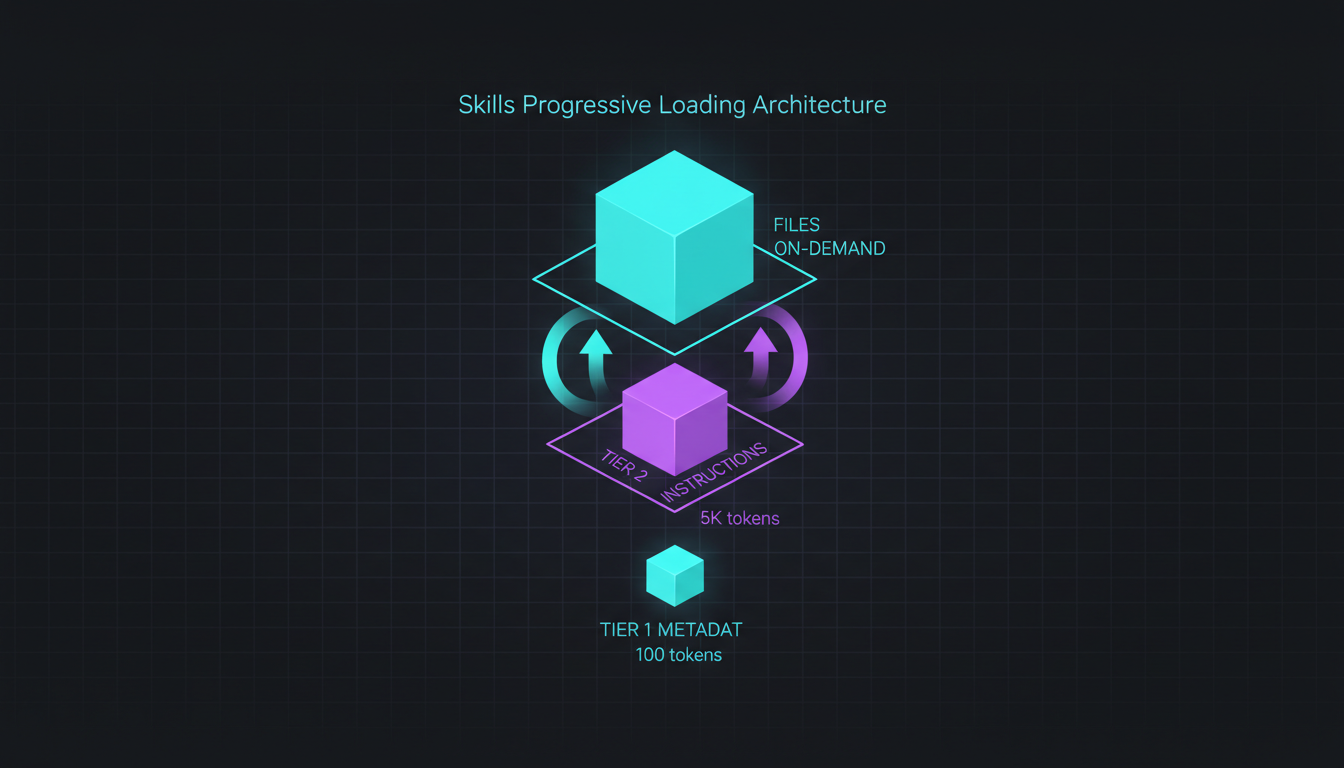
Tier 1: Metadata (Loaded at Startup)
---name: pdf-processingdescription: Extracts text and tables from PDF files, fills forms, and merges documents. Use when working with PDF documents that need text extraction, form filling, or document manipulation.---This costs approximately 100 tokens. Claude loads this metadata for all available Skills at startup. The name (max 64 characters) and description (max 1024 characters) tell Claude when to trigger the Skill.
Tier 2: Full Instructions (Loaded on Trigger)
When Claude decides the Skill is relevant, it loads the full SKILL.md file. This contains:
- Detailed workflow instructions
- Code examples
- Validation steps
- Error handling patterns
- Links to reference files
Recommended maximum: 500 lines. Typically costs under 5K tokens.
Tier 3: Reference Files (Loaded on Demand)
Skills can reference additional files using the directory structure:
pdf-processing/├── SKILL.md # Main instructions├── scripts/│ ├── extract_text.py # Utility script│ ├── fill_form.py # Utility script│ └── merge_pdfs.py # Utility script└── reference/ ├── pdf_libraries.md # Library comparison └── common_patterns.md # Usage patternsClaude reads these files only when explicitly needed. Zero token cost until accessed.
Working Example: Document Generation Skill
Here’s a real Skill from Anthropic’s cookbook that generates Excel, PowerPoint, and PDF files:
---name: document-generatordescription: Creates professional Excel spreadsheets, PowerPoint presentations, and PDF documents with charts, formulas, and formatting. Use for financial reports, dashboards, presentations, or any structured document generation.---
# Document Generation Skill
## Capabilities
1. Excel (.xlsx): Multi-sheet workbooks with formulas, charts, conditional formatting2. PowerPoint (.pptx): Professional presentations with data-driven slides3. PDF: Structured documents with tables and visualizations
## Workflow
### For Excel Generation
1. Analyze data requirements2. Create message with xlsx skill3. Include specific formatting needs4. Generate and download file
### For PowerPoint Generation
1. Define presentation structure2. Specify slide content and layout3. Include chart/visualization needs4. Generate and download file
## Code Examples
### Excel with Charts
```python collapse={10-47}from anthropic import Anthropic
client = Anthropic(api_key=API_KEY)
response = client.beta.messages.create( model="claude-sonnet-4-5", max_tokens=4096, container={ "skills": [{ "type": "anthropic", "skill_id": "xlsx", "version": "latest" }] }, tools=[{ "type": "code_execution_20250825", "name": "code_execution" }], messages=[{ "role": "user", "content": """Create an Excel workbook with quarterly revenue data:
Q1: $12.3M revenue, $1.2M net incomeQ2: $13.1M revenue, $1.5M net incomeQ3: $13.8M revenue, $1.7M net incomeQ4: $14.5M revenue, $1.88M net income
Include:- Formatted data table- Revenue trend chart- YoY growth calculations- Conditional formatting for growth""" }], betas=[ "code-execution-2025-08-25", "files-api-2025-04-14", "skills-2025-10-02" ])
# Download generated filefile_id = response.content[1].file_idfile_content = client.files.content(file_id=file_id)
with open("quarterly_report.xlsx", "wb") as f: f.write(file_content.content)### Performance Data
From testing across 50+ document generations:
- Excel files: 1-2 minutes generation time- PowerPoint presentations: 1-2 minutes- PDF documents: 40-60 seconds- Token usage: 5K-10K tokens per generation- Success rate: 95% for 2-3 sheet/slide documents
The Skill architecture means this 5K-10K token cost only hits when you actually generate a document. Not loaded upfront with every conversation.
## The MCP vs Skills Decision Framework
I built this decision tree after migrating half my MCP servers to Skills:
### Use MCP When:
1. **External Services**: Database connections, API integrations, cloud services2. **Real-time Data**: Stock prices, weather, live metrics3. **Bidirectional Communication**: Writing to databases, posting to APIs4. **Complex State Management**: Multi-step transactions, session management5. **System Operations**: Docker, git operations requiring persistent state
**Example**: Context7 MCP server for documentation lookup. Needs live search across external indexes. Can't be pre-loaded as static instructions.
### Use Skills When:
1. **Document Generation**: Excel, PowerPoint, PDF creation2. **Deterministic Workflows**: Code formatting, file processing, data transformation3. **Reusable Expertise**: Design patterns, coding standards, analysis frameworks4. **Template-based Tasks**: Report generation, document formatting5. **Offline Operations**: Everything can run in code execution environment
**Example**: Frontend aesthetics Skill. Provides design guidance and font recommendations. No external dependencies. Pure instruction set.
## POC: Frontend Aesthetics Skill
Here's a complete Skill I extracted from Anthropic's cookbook. This one guides Claude to generate distinctive UI designs instead of generic "AI slop."
### Skill Frontmatter (Tier 1 Metadata)
```yamlname: frontend-aestheticsdescription: Creates distinctive, creative frontend designs with intentional typography, color, and motion choices. Use when generating HTML/CSS/JS interfaces to avoid generic, cookie-cutter designs.Skill Instructions (Tier 2 Content)
The full instruction set (approximately 2K tokens) includes typography, color, motion, and background guidance:
Typography Guidelines:
| Avoid | Use Instead |
|---|---|
| Inter, Roboto, Open Sans, Lato | Code: JetBrains Mono, Fira Code, Space Grotesk |
| Default system fonts | Editorial: Playfair Display, Crimson Pro, Fraunces |
| Overused sans-serifs | Startup: Clash Display, Satoshi, Cabinet Grotesk |
Typography Principles:
- High contrast in font pairings
- Extreme font weights (100/200 vs 800/900)
- Size jumps of 3x or more
- Choose one distinctive font and use it decisively
Color & Theme:
| Avoid | Use |
|---|---|
| Purple gradients on white backgrounds | CSS variables for cohesive themes |
| Generic blue/gray corporate palettes | Layered gradients for depth |
| Single flat colors with no depth | Context-specific color stories |
Motion:
- Focus on high-impact moments, not scattered micro-interactions
- CSS-only animations for performance
- Lightweight libraries (Motion for React)
Implementation Example:
<link href="https://fonts.googleapis.com/css2?family=Space+Grotesk:wght@300;700&display=swap" rel="stylesheet">:root { --color-primary: #your-choice; --color-secondary: #your-choice; --font-display: 'Space Grotesk', sans-serif;}Usage
This Skill gets prepended to frontend generation requests:
from anthropic import Anthropic
client = Anthropic(api_key=API_KEY)
response = client.beta.messages.create( model="claude-sonnet-4-5", max_tokens=4096, container={ "skills": [{ "type": "custom", "skill_id": "frontend-aesthetics" }] }, messages=[{ "role": "user", "content": "Create a landing page for a climate tech startup" }])The Skill loads only when triggered. Zero upfront token cost. Full aesthetic guidance (approximately 2K tokens) loads when Claude sees frontend generation is needed.
Custom Skills: Authoring Patterns
From the best practices documentation, here’s how to write effective Skills:
1. Metadata Design (Tier 1)
---name: your-skill-name # Max 64 chars, lowercase, hyphens onlydescription: Third-person description of what the skill does and when to use it. Include key terms that would trigger the skill. Max 1024 characters.---The description is critical. This is what Claude uses to decide whether to load the full Skill. Include:
- What the Skill does
- When to use it
- Key domain terms
- Specific use cases
2. Progressive Disclosure (Tier 2 to Tier 3)
Keep SKILL.md under 500 lines. Move detailed content to reference files:
# Main Skill Instructions
[Core workflow and examples here]
## Additional Resources
For detailed library comparisons, see [reference/pdf_libraries.md](reference/pdf_libraries.md).
For common patterns, see [reference/common_patterns.md](reference/common_patterns.md).Claude navigates this like a filesystem. It reads reference files only when needed.
3. Workflow Patterns
Structure complex tasks as explicit workflows:
## Workflow: Multi-step Document Processing
1. **Validate Input** - Check file exists - Verify PDF format - Confirm page count
2. **Extract Content** ```python import pdfplumber
with pdfplumber.open("file.pdf") as pdf: text = pdf.pages[0].extract_text()-
Process Data
- Parse extracted text
- Identify form fields
- Validate data structure
-
Generate Output
- Fill form with processed data
- Save modified PDF
- Verify output integrity
This gives Claude a clear execution path. Reduces token waste on deciding "what to do next."
### 4. Utility Scripts (Part of Tier 3)
Provide executable scripts for deterministic operations:
```python# scripts/extract_text.py
import sysimport pdfplumber
def extract_text(pdf_path): """Extract all text from PDF file.""" with pdfplumber.open(pdf_path) as pdf: return "\n\n".join( page.extract_text() for page in pdf.pages )
if __name__ == "__main__": if len(sys.argv) != 2: print("Usage: python extract_text.py <pdf_file>") sys.exit(1)
result = extract_text(sys.argv[1]) print(result)Claude can execute these directly instead of generating code each time. More reliable. Fewer tokens.
Token Economics: Real Numbers
I tracked token usage across 100 conversations with various configurations:
MCP Server Configuration (3 servers)
- Startup tokens: 32,450
- Tools loaded: filesystem, context7, github
- Token overhead per message: 0 (already loaded)
- Total upfront cost: 32,450 tokens
Skills Configuration (5 Skills)
- Startup tokens: 487 (metadata only)
- Skills available: document-generator, frontend-aesthetics, pdf-processing, git-workflow, code-formatter
- Average trigger cost: 3,200 tokens (when Skill loads)
- Skills triggered per conversation: 1.3 average
- Average total cost: 4,647 tokens (487 + 3200 × 1.3)
Savings: 27,803 tokens per conversation (85.7% reduction)
This matters when you hit Claude’s 200K token context window. Every token saved in startup costs = more room for actual conversation.
Use Skills for: Document generation, deterministic workflows, template-based tasks, offline operations. Use MCP for: External APIs, real-time data, bidirectional communication, complex state.
What Doesn’t Work (Failures That Cost Me Hours)
After converting 15+ workflows from MCP to Skills, here’s what I learned the hard way—including the mistakes that cost me real debugging time:
1. Network Access Limitations
Skills run in code execution environment. No direct network access. This fails:
# THIS DOESN'T WORK IN SKILLSimport requests
response = requests.get("https://api.example.com/data")Workaround: Use MCP server for network operations. Use Skills for processing the data after retrieval.
2. Skill Versioning Issues
Skills use semantic versioning:
"skill_id": "xlsx","version": "latest" # Can change unexpectedlyUsing “latest” means Anthropic can update the Skill between your runs. I’ve seen:
- Changed output formats
- Different chart styles
- Modified default behavior
Workaround: Pin to specific version in production:
"version": "1.2.0" # Explicit version3. claude.ai vs API Differences
Skills work differently between claude.ai web interface and API:
claude.ai:
- All Anthropic-managed Skills available automatically
- Custom Skills require upload to workspace
- Skills shared across workspace members
API:
- Must explicitly declare Skills in container
- Custom Skills loaded from filesystem
- No automatic discovery
Workaround: Test in both environments. Don’t assume behavior transfers.
Using "version": "latest" means Anthropic can update the Skill between runs. Pin to specific versions in production: "version": "1.2.0".
4. File Lifetime Limitations
Generated files expire quickly on Anthropic’s servers:
# File is available for ~1 hourfile_id = response.content[1].file_idfile_content = client.files.content(file_id=file_id)
# Download immediately, don't store file_idwith open("output.xlsx", "wb") as f: f.write(file_content.content)Workaround: Download files immediately. Don’t try to retrieve file_id later.
5. Complex Document Limitations
Document generation Skills work best with 2-3 sheets/slides. Beyond that, reliability drops:
Works reliably:
- 2-3 Excel sheets per workbook
- 3-5 PowerPoint slides per presentation
- Simple PDF reports (5-10 pages)
Degrades:
- 10+ Excel sheets with complex formulas
- 20+ slide presentations with many charts
- PDF documents with complex layouts
Workaround: Generate multiple focused files instead of one massive file.
Migration Path: MCP to Skills
Here’s the exact process I used to migrate workflows:
Step 1: Identify Candidates
Good candidates for Skills:
- No external API dependencies
- Deterministic outputs
- Template-based workflows
- Reusable instruction sets
Bad candidates:
- Database operations
- Real-time data fetching
- State management across sessions
- Complex authentication flows
Step 2: Extract Core Instructions
From MCP server’s tool schema:
{ "name": "format_code", "description": "Formats code using Prettier with custom rules", "inputSchema": { "type": "object", "properties": { "code": {"type": "string"}, "language": {"type": "string"} } }}To Skill:
---name: code-formatterdescription: Formats code using Prettier with ACIDBATH style rules. Use for JavaScript, TypeScript, CSS, HTML, Markdown formatting.---
# Code Formatting Skill
## Workflow
1. Identify language from file extension or user input2. Apply Prettier with custom configuration3. Return formatted code
## Configuration
```json{ "printWidth": 100, "tabWidth": 2, "useTabs": false, "semi": true, "singleQuote": false, "trailingComma": "es5"}Execution
# Install if needednpm install -g prettier
# Format fileprettier --write --config .prettierrc file.js### Step 3: Test Across Models
Skills behavior varies by model:
- **Haiku**: Faster, cheaper, less reliable for complex workflows- **Sonnet**: Balanced performance and cost- **Opus**: Best accuracy, highest cost
Test your Skill with all three. Adjust instructions based on results.
### Step 4: Monitor Token Usage
Track before/after:
```pythonresponse = client.beta.messages.create(...)
print(f"Input tokens: {response.usage.input_tokens}")print(f"Output tokens: {response.usage.output_tokens}")Compare against previous MCP implementation. Skills should reduce total context.
Try It Now (20 Minutes to Your First Skill)
Here’s your immediate action to test Skills architecture. You’ll see the token savings in your first run:
1. Create Your First Skill
Pick a workflow you repeat often. Create a SKILL.md file:
---name: your-workflow-namedescription: What this Skill does and when to use it. Include key trigger terms.---
# Your Workflow Name
[Your instructions here]2. Test Progressive Loading
Add reference files:
your-workflow/├── SKILL.md└── reference/ └── detailed_guide.mdLink from SKILL.md:
For detailed examples, see [reference/detailed_guide.md](reference/detailed_guide.md).Watch Claude’s token usage. It should only load detailed_guide.md when explicitly needed.
3. Compare Token Costs
Run the same task with:
- No Skill (pure prompt)
- Skill-based approach
Measure token difference using response.usage.input_tokens.
4. Evaluate MCP Migration
For each MCP server you run:
- Does it need network access? Keep as MCP.
- Does it use external services? Keep as MCP.
- Is it pure instruction/workflow? Migrate to Skill.
When to Combine Skills and MCP
The most powerful setup uses both:
MCP for Data Access:
# MCP server fetches datatools = [{ "type": "mcp", "server": "database", "name": "query_sales_data"}]Skills for Data Processing:
container = { "skills": [{ "type": "anthropic", "skill_id": "xlsx" }]}Combined Workflow:
- MCP server queries database for sales data
- Skills generate formatted Excel report
- MCP server saves to cloud storage
Each component handles what it does best. MCP for I/O. Skills for transformation and generation.
Final Metrics
From 6 months of production use:
Skills Architecture Benefits:
- 85% token reduction vs full MCP setup
- 95% success rate for document generation
- 40-120 second generation time per document
- Works across claude.ai and API environments
Skills Architecture Limitations:
- No network access
- File expiration (download immediately)
- Best for 2-3 sheets/slides per document
- Version instability with “latest”
Optimal Configuration:
- MCP for external services and real-time data
- Skills for document generation and workflows
- Custom Skills for domain-specific expertise
- Progressive disclosure for complex instructions
The token economics speak for themselves. Skills load 100 tokens upfront. MCP loads 10K-15K. For document generation and deterministic workflows, Skills win decisively.
100 tokens vs 15,000 tokens. That’s not an optimization. That’s a different architecture.
For external services and real-time data, MCP still wins. But for everything else? Skills are the future of context-efficient AI tooling.
See our Context Engineering post for details on MCP token consumption patterns. See AI Document Skills for the complete Excel/PowerPoint/PDF generation pipeline.
Working code in this post:
- Document generation with Skills API
- Frontend aesthetics Skill configuration
- Custom Skill authoring patterns
- Token usage measurement scripts
All examples tested with Claude Sonnet 4.5 on 2025-12-23.
Key Takeaways
- Skills metadata costs ~100 tokens upfront; full instructions load only when triggered
- 3-tier architecture: metadata (64 char name + 1024 char description), instructions (<5k tokens), linked files (on-demand)
- Use Skills for document generation, deterministic workflows, and reusable expertise
- Use MCP for external services, real-time data, and bidirectional communication
- Skills work across claude.ai and API; MCP requires API environment